#背景知识
抽象语法树 (Abstract Syntax Tree, AST) 是源代码结构的一种抽象表示,它以树的形状表示语言的语法结构。抽象语法树一般可以用来进行代码语法的检查,代码风格的检查,代码的格式化,代码的高亮,代码的错误提示以及代码的自动补全等等。
#简介
ANTLR v4 是一款功能强大的语法分析器生成器,可以用来读取、处理、执行和转换结构化文本或二进制文件。它被广泛应用于学术界和工业界构建各种语言、工具和框架。Antlr4 生成的解析器包含了词法分析程序和语法分析程序,没错,这就是编译原理课程中的词法分析和语法分析。
html<title><div>111</div></title>
上面代码经过 Antlr 解析后便成了下图
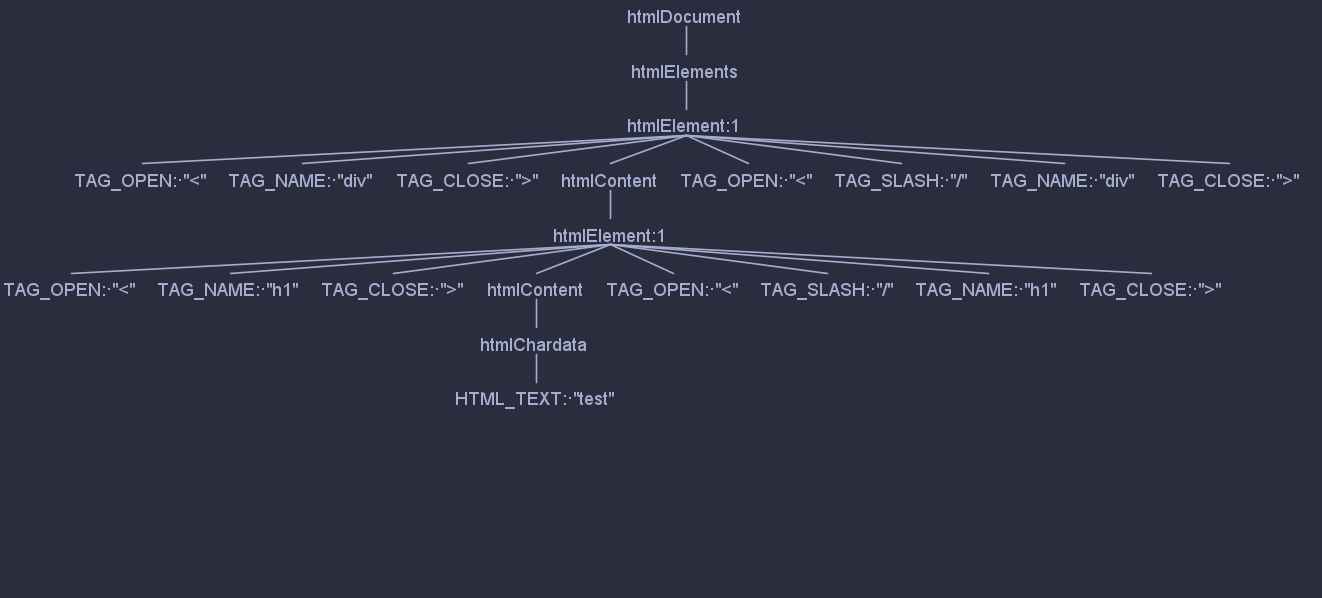
#它做了什么?
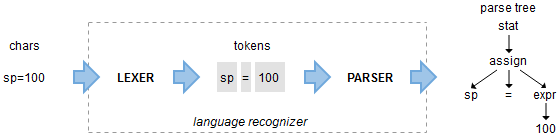
词法分析( lexical analysis ) + 语法分析( syntax analysis )
- 词法分析 —— 读取字符流,将字符识别为各种 Token ,标记好类别。比如下图中的赋值语句
sp=100,词法分析后得出sp=100三个 Token。 - 语法分析 —— 语法分析通过解析词法分析生成的 Token 来识别语句结构,它一般不在乎符号的内容,只关心它们的类型。上边的语句经过语法分析后,就会得出这是
赋值语句的结论。
ANTLR v4 的语法规则分为词法 (Lexer) 规则和语法 (Parser) 规则:词法规则定义了怎么将代码字符串序列转换成标记序列;语法规则定义怎么将标记序列转换成语法树。通常,词法规则的规则名以大写字母命名,而语法规则的规则名以小写字母开始。
#Antlr 语法规则
ruleName: alternative1 | alternative2 | alternative3 ;
Antlr 4 的每条rule结构如上,这条语法规则申明一条名为 ruleName 的rule,其中 | 表名为分支、即该 rule 可以匹配三个分支中的任何一个。
- 注释:和 Java 的注释完全一致 // 单行注释 /* */ 多行注释;
- 标志符:参考 Java 或者 C 的标志符命名规范,针对 Lexer 部分的 Token 名的定义,采用全大写字母的形式,对于 parser rule 命名,推荐首字母小写的驼峰命名;
- 不区分字符和字符串,都是用单引号引起来的,同时,虽然 Antlr g4 支持 Unicode 编码(即支持中文编码),但是建议大家尽量还有英文;
详情查看官方文档
#Import
import语法可以将语法文件变得可复用性更强
Tips:
- Lexer 语法能导入 Lexer 语法
- Parser 语法能导入 Parser 语法
- 统一写的语法**(combined grammars)**文件可以导入 Lexer 或 Parser
import语法不会引入已经定义好的rule
grammar Expr;
import Expr1, Expr2;
#Tokens
tokens是用来定义没有关联词法rule的 token
lexer gammar ExprLexer;
tokens { Token1, ..., TokenN }
#Action
行为,主要有 @header 和 @members,用来定义一些需要生成到目标代码中的行为,例如,可以通过 @header 设置生成的代码的 package 信息,@members 可以定义额外的一些变量到 Antlr4 语法文件中。
统一写的语法文件里,action 需要限制性质,@parser::name 或 @lexer:name
grammar Count;
@header {
package foo;
}
@members {
int count = 0;
}
list
@after {System.out.println(count+" ints");}
: INT {count++;} (',' INT {count++;} )*
;
INT : [0-9]+ ;
WS : [ \r\t\n]+ -> skip ;
#词法规则 (lexer)
#基础
grammar Hello; // 定义文法的名字
s : 'hello' ID ; // 匹配关键字hello和标志符
ID : [a-z]+ ; // 标志符由小写字母组成
WS : [ \t\r\n]+ -> skip ; // 跳过空格、制表符、回车符和换行符
TOKEN: TEST
| 语法 | 描述 |
|---|---|
| T (冒号左边的) | 在当前行匹配 token T。Token 通常以大写字母开头,对应上方代码中的 TOKEN |
| T (冒号右边的) | 调用规则 T ,可以是token 也可以是 fragment 中的 rule,对应上方代码中的 TEST |
| ’x’ | 匹配单引号内的字符序列,如 ’while’ 或者 ’=’ |
| [xyz] | 匹配中括号内的字符,比如 [1-9] 即匹配 1 到 9 之间的值。 |
| 'x'..'y' | 匹配 x 和 y 之间的任意字符。'a'..'z' 等价于 [a-z] |
| . | 匹配任意一个值 |
| ~x | 匹配任意不在x中的值 |
| x? | 匹配 x 0 次 或 1 次 |
| X* | 匹配 x 0 次以上 |
| x+ | 匹配 x 1 次以上 |
| x | y | x 或 y |
| {«action»} | 示例: `END : ('endif' |
| {«p»}? | 语义断言 «p»。如果在运行环境中,该断言判断为 false ,那么其附近的rule将会变为“不可见的”,同样地, «p»中的指令应跟目标语言的语法一致。 详情见官方文档 需要注意的是,语义断言需在 action 之前 |
#Fragment
在fragment下可以定义不是 token 但可以用来帮助识别 token 的规则
比如 DIGIT 是个很常见的 fragment rule。使用 fragment 前缀来定义,ANTLR 就会知道这条rule仅仅用来组成其它词法规则,而不会单独使用。DIGIT 本身并不是我们需要的符号,也就是说,我们在语法分析器中是看不到 DIGIT 这个符号的。
INT : DIGIT+ ; // 引用 DIGIT rule
fragment
DIGIT : [0-9] ; // 不是一个 token
#Mode
mode 允许以上下文的形式将rule分组。Lexer 仅能匹配当前 mode 下的rule,所有没定义 mode 的rule将会被归于默认 mode 中。mode仅能在 Lexer 中定义,不能在统一语法文件中。
mode 可通过 pushMode(modeName) 进入,popMode退出
lexer grammar HTMLLexer;
// rules in default mode
TAG_OPEN
: '<' -> pushMode(TAG)
;
mode TAG;
// rules in TAG mode
TAG_CLOSE
: '>' -> popMode
;
TAG_SLASH_CLOSE
: '/>' -> popMode
;
#递归
Antlr 的词法规则可以是递归的,这样的话想要匹配嵌套语法就很方便了
lexer grammar Recur;
ACTION : '{' ( ACTION | ~[{}] )* '}' ;
WS : [ \r\t\n]+ -> skip ;
Antlr 4 可以处理直接的左递归,但不能处理间接的左递归。
expr : expr '*' expr // 直接的左递归
| addExpr // 间接的左递归
;
addExpr : expr '+' expr ;
#重复声明Rule
不同rule名,但右边是一样的话,在 antlr 里是不允许的。但是在不同 mode中却是可行的。如:
lexer grammar L;
AND : '&' ;
mode STR;
MASK : '&' ;
Parser 语法里不能识别单纯的 '&',但可以识别 token 名(因为不同mode)
parser grammar P;
options { tokenVocab=L; }
a: '&' // 识别不了
| AND // 没问题
| MASK // 没问题
;
#指令
Antlr 的指令写在rule后面,需要用 ->连接。和action一样,一个 token 后只能有一个指令,可以用,分割多个指令
TokenName : «alternative» -> 指令名
TokenName : «alternative» -> 指令名 («identifier or integer»)
可用的指令名:
- skip
- more
- popMode
- mode(x)
- pushMode(x)
- type(x)
- channel(x)
#skip
skip命令可以告诉 Lexer 跳过当前 token
ID : [a-zA-Z]+ ; // 匹配标识符
INT : [0-9]+ ; // 匹配整数
NEWLINE:'\r'? '\n' ; // 匹配换行
WS : [ \t]+ -> skip ; // 不要识别空格和 tab
#mode(), pushMode(), popMode() 和 more
通过这些指令可以切换 Lexer 的 mode 栈, more指令可以在不退出当前 mode 的同时识别其他 mode 的rule。
#type()
切换为某个 token 名。多个 type()指令的话,只有最右边的生效
lexer grammar SetType;
tokens { STRING }
DOUBLE : '"' .*? '"' -> type(STRING) ;
SINGLE : '\'' .*? '\'' -> type(STRING) ;
WS : [ \r\t\n]+ -> skip ;
#channel()
放到 channel (HIDDEN) 中的 Token,不会被语法解析阶段处理,但是可以通过 Token 遍历获取到。
BLOCK_COMMENT
: '/*' .*? '*/' -> channel(HIDDEN)
;
LINE_COMMENT
: '//' ~[\r\n]* -> channel(HIDDEN)
;
...
// ----------
// Whitespace
//
// 对人类需要看到,但是对于编译器不需要
// 看到的字符,可以选择隐藏
//
//
WS : [ \t\r\n\f]+ -> channel(HIDDEN) ;
Antlr 4.5 版本后,可以像下面这样定义 channel,只有 Lexer 语法可以自定义 channel。
channels { WSCHANNEL, MYHIDDEN }
#语法规则 (Parser)
#基础
Parser 主要是定义目标语言的语法规则,比如识别编程语言中的声明语句
| 语法 | 描述 |
|---|---|
| r (冒号左边的) | 在当前行匹配 rule r。rule通常以小写字母开头 |
| T (冒号右边的) | 匹配 Token T ,即 Lexer 中的 Token |
| ’x’ | 同 Lexer |
| r [«args»] | 像执行函数一样匹配 rule r 的同时传入中括号内定义的一系列参数。 参数的语法与生成目标语言一致 多个表达式以,分隔 |
| . | 同 Lexer |
| ~x | |
| x? | |
| X* | |
| x+ | |
| x | y | |
| {«action»} | |
| {«p»}? |
#可选项标签
通过给语法rule的各个可选项 (alternative) 加上# 标签 可以获得更准确的编译信息。
注意:要么给全部可选项加上标签,要么就全都不加
grammar T;
sentence
: TEXT* expression TEXT* (END_SIGN|NL)* # TextWithExpression
| expression END_SIGN? # ExpressionOnly
| TEXT (END_SIGN|NL)* # TextOnly
;
#Rule 内容对象
Antlr 会生成可以访问每一条rule内容的方法(与引用rule名有关),比如下面 rule 中 expression 引用了 expr:
parser grammar TestParser;
expression
: EXPR_START EXPR_TYPE EXPR_HASH expr EXPR_END
;
Antlr 生成的对象则为:
public static class ExpressionContext extends ParserRuleContext {
public ExprContext expr() { ... } // return context object associated with expr
...
}
如果有多个对 expr 的引用,也是可以的:
parser grammar TestParser;
expression
: EXPR_START EXPR_TYPE EXPR_HASH expr EXPR_HASH expr EXPR_END
;
那么就会生成如下:
public static class ExpressionContext extends ParserRuleContext {
public ExprContext expr(int i) { ... } // 获取单独的内容
public List<ExprContext> expr() { ... } // 获取所有的 expr 内容
...
}
#Rule 元素标签
可以使用=符号给rule元素加上标签(别名?)
parser grammar TestParser;
expression
: EXPR_START EXPR_TYPE EXPR_HASH sentence=expr EXPR_END
;
那么 Antlr 生成的类则是:
public static class ExpressionContext extends StatContext {
public ExprContext sentence;
...
}
#异常捕获
每一条 rule 都被包裹在 try/catch/finally中
参考官方文档
#Start Rule 和 EOF
Start Rule 是被 Parser 解析的第一个 rule,所有 rule 都可以作为 Start Rule。
#解决歧义
#优先级
靠前的规则可选项优先级更高
expr : expr '*' expr // 乘法运算写在前边,会被优先匹配
| expr '+' expr
;
#右结合
如指数运算2 ^ 5 ^ 7是右结合的,需要先计算5 ^ 7,可以使用assoc来指定结合性
expr : expr '^'<assoc=right> expr // 指定右结合
| INT
;
#实现解析简单运算
lexer grammar ExprLexer;
MUL : '*' ;
DIV : '/' ;
ADD : '+' ;
SUB : '-' ;
LPAREN : '(' ;
RPAREN : ')' ;
ID : LETTER (LETTER | DIGIT)* ;
INT : [0-9]+ ;
EQ : '=' ;
SEMI : ';' ;
COMMENT : '//' ~[\r\n]* '\r'? '\n'? -> channel(HIDDEN);
WS : [ \r\n\t]+ -> channel(HIDDEN);
fragment
LETTER : [a-zA-Z] ;
fragment
DIGIT : [0-9] ;
parser grammar ExprParser;
options { tokenVocab = ExprLexer; }
prog
: stat+ ;
stat
: exprStat
| assignStat
;
exprStat
: expr SEMI
;
assignStat
: ID EQ expr SEMI
;
expr
: expr op = (MUL | DIV ) expr # MulDivExpr
| expr op = ( ADD | SUB ) expr # AddSubExpr
| INT # IntExpr
| ID # IdExpr
| LPAREN expr RPAREN # ParenExpr
;
#最佳实践
#非贪婪匹配
很多开发语言都支持多行注释,比如 Java 或 C 指定在 /* 与 */ 之间的任意字符都是注释的内容。ANTLR 默认使用贪婪匹配的原则,如果一个文件内有多块注释,那么从第一个 /* 一直到最后一个 */ 之间的所有内容都会被匹配为注释内容。所以对于这类的语法定义需要使用非贪婪匹配:
comment : '/*' .*? '*/'; // *?表示非贪婪匹配
#将词法符号送入不同通道
ANTLR 支持在词法分析阶段将词法符号放到不同的通道,除了默认通道,其他自定义的通道都是隐藏的,对语法分析不可见。比如,分析并运行 Java 文件的应用并不关心文件里的空白字符和注释,这些不关心的内容可以放入丢弃通道,接下来的语法分析会忽略这部分内容,加快分析的速度。把某种语言翻译成另一种语言的应用,如果两种语言有一部分相同的语法,可以把这部分内容送入单独的通道,略过语法分析,在最后的翻译应用中再取出复制。下边是对内置丢弃通道 skip通道与自定义通道的使用示例:
@lexer::members {
public static final int COMMENTS = 1; // 非ANTLR内置的通道需要定义
}
COMMENT : '\\' .*? '\n' -> channel(COMMENTS) ; // 将注释放入COMMENTS通道
WS : [ \t\n\r]+ -> skip ; // 将空白字符放入skip通道,skip通道是ANTLR内置的通道,传入的符号将被丢弃
#处理同一文件中的不同格式
有一些语言,其结构化的区域被随机文本所包围,被称为孤岛语言(island language)。比如 XML 或 HTML,<> 之内包裹的部分是结构化的标签,而外部则是大片我们不关心的文本。处理这一类语言就需要用到mode。下边以一个简化的 XML 语法为例:
file : (tag | TEXT)* ;
tag : '<' ID '>'
| '<' '/' ID '>'
;
OPEN : '<' -> mode(TAG) ; // 切换到TAG模式
TEXT : ~'<'+ ;
mode TAG; // 从此处向下的部分为TAG模式的词法
CLOSE : '>' -> mode(DEFAULT_MODE) ; // 返回默认模式
SLASH : '/' ;
ID : [a-zA-Z]+ ;